

Почему VPS от ERPC обеспечивает высокую производительность
Почему VPS от ERPC обеспечивает высокую производительность

Когда разработчики начинают создавать приложения или ботов на Solana, многие по привычке выбирают крупные универсальные облака.
В мире Web2 это давно стало почти стандартом, и такой подход действительно обеспечивает достаточную производительность.
Поэтому вполне естественно предположить, что для Solana он тоже подойдет.
В мире Web2 это давно стало почти стандартом, и такой подход действительно обеспечивает достаточную производительность.
Поэтому вполне естественно предположить, что для Solana он тоже подойдет.
Но именно для Solana это предположение быстро перестает работать.
Крупные универсальные облака проектируются вокруг гибкости и универсальности, а в задачах, где задержка напрямую влияет на результат, их структурные ограничения проявляются сразу.
Крупные универсальные облака проектируются вокруг гибкости и универсальности, а в задачах, где задержка напрямую влияет на результат, их структурные ограничения проявляются сразу.
В этой статье мы подробно разберем, почему нагрузки Solana редко достигают ожидаемой производительности в крупных облаках общего назначения и как устроен VPS от ERPC, чтобы решать эти проблемы.
Почему в Web2 «медлительность облака» почти никто не замечал
Для начала важно помнить: большинство Web2-приложений не настолько критичны, как финансовые системы.
Социальные сети, e-commerce, корпоративные инструменты и сервисы доставки контента могут выдержать определенную задержку и при этом оставаться рабочими продуктами.
Социальные сети, e-commerce, корпоративные инструменты и сервисы доставки контента могут выдержать определенную задержку и при этом оставаться рабочими продуктами.
Именно поэтому следующие источники структурной задержки внутри крупных облаков долго не воспринимались как проблема:
- Несколько слоев виртуализации (virtual NICs, virtual switches и т.д.)
- Внутренняя полоса пропускания, которую делят между собой многие пользователи
- CPU overcommit, когда виртуальных ядер выдано больше, чем физических
- Дополнительные процессы для биллинга и мониторинга
- Более старые поколения CPU, которые обычно и попадают в доступные пользователю конфигурации
Все эти механизмы необходимы облачной платформе, но для Web2-нагрузок их влияние обычно невелико и почти не заметно.
С Solana ситуация принципиально иная.
Web3-приложения находятся рядом с финансами, а значит всё становится критически важным
Приложения на Solana и других блокчейнах находятся очень близко к финансовому домену.
Движение активов, условия ликвидации, изменение цен и порядок транзакций напрямую влияют на результат.
Движение активов, условия ликвидации, изменение цен и порядок транзакций напрямую влияют на результат.
Особенно заметно это в рыночных сценариях, где объем и скорость обработки значительно выше, чем в обычных карточных платежах.
Даже несколько миллисекунд задержки могут означать неисполнение сделки или худшую цену.
Даже несколько миллисекунд задержки могут означать неисполнение сделки или худшую цену.
Кроме того, объем ончейн-данных в Solana огромен. Если корректно подписаться на Shreds, логи и события gRPC, суточный объем трафика легко уходит в несколько терабайт.
Это совсем не тот профиль трафика, под который исторически проектировались большие универсальные облака.
Это совсем не тот профиль трафика, под который исторически проектировались большие универсальные облака.
Поэтому скрыть структурную задержку или ценовые особенности облака в случае с Solana уже не получается.
Они сразу превращаются либо в потерю производительности, либо в прямые операционные расходы.
Они сразу превращаются либо в потерю производительности, либо в прямые операционные расходы.
Почему большие универсальные облака плохо подходят для Solana
Ниже по пунктам разберем, почему высокоскоростные нагрузки Solana плохо сочетаются с устройством крупных облачных платформ.
1. Пользователям обычно достаются CPU нескольких поколений назад
серверы bare metal и VPS (VMs), которые крупные облака отдают в общий доступ, чаще всего используют CPU, отстающие на несколько поколений от новейших решений.
Новейшие high-clock CPU плохо вписываются в закупочную стратегию и операционную модель провайдера, поэтому в пользовательских конфигурациях встречаются редко.
Новейшие high-clock CPU плохо вписываются в закупочную стратегию и операционную модель провайдера, поэтому в пользовательских конфигурациях встречаются редко.
Для Solana важны производительность одного потока и структура кэша, и поколение CPU напрямую влияет на:
- Сколько транзакций реально удаётся обрабатывать
- Сколько потоков можно удерживать без отставания
- Насколько быстро обрабатываются данные
2. Много слоёв виртуализации и длинный сетевой путь
Крупные универсальные облака должны одновременно поддерживать множество разных нагрузок на одном физическом "железе".
Из-за этого поверх физической машины строится несколько уровней виртуализации и внутренней сети.
Из-за этого поверх физической машины строится несколько уровней виртуализации и внутренней сети.
Например:
- Гипервизоры для запуска VMs
- Virtual NICs и switches
- Внутренние firewalls и load balancers
- Агенты биллинга и мониторинга
Для облачной платформы все это необходимо, но с точки зрения Solana:
- Каждый такой слой удлиняет путь обработки
- Каждый из них добавляет задержку и jitter
Если нагрузка постоянно получает потоковые данные, например через Shreds или gRPC, все эти дополнительные промежуточные точки становятся прямым недостатком.
3. Overcommit делает производительность нестабильной
Крупные облака повышают эффективность, запуская много виртуальных машин на одном физическом сервере.
Например, на сервере с физическим 64-ядерным CPU может быть размещено множество 8- или 16-ядерных VMs, суммарно заметно больше 64 виртуальных ядер.
Например, на сервере с физическим 64-ядерным CPU может быть размещено множество 8- или 16-ядерных VMs, суммарно заметно больше 64 виртуальных ядер.
Такой подход и называется overcommit.
Он строится на двух предположениях:
- Не все VMs будут одновременно использовать 100% CPU
- Процессорное время можно перераспределять между машинами в зависимости от активности
Для Web2-нагрузок это часто работает вполне приемлемо.
Но нагрузки Solana нередко состоят из нескольких процессов, которым одновременно нужен серьезный CPU.
На overcommitted-сервере contention возникает чаще, и операционная система начинает распределять задачи через очередь.
На overcommitted-сервере contention возникает чаще, и операционная система начинает распределять задачи через очередь.
В результате:
- Бенчмарк может показывать хорошие числа
- Но реальная задержка под боевой нагрузкой начинает сильно зависеть от времени суток и активности соседних арендаторов
Для Solana, где момент отправки транзакции или обработки потока данных напрямую влияет на результат, такой jitter уже становится серьезной проблемой.
4. Большой объем передачи данных превращается в дорогую тарификацию по потреблению
Серьезная работа с ончейн-данными Solana часто означает несколько терабайт трафика в день через Shreds, логи и события gRPC.
Крупные облака отдельно тарифицируют:
- Исходящий сетевой трафик
- Иногда и внутренний сетевой трафик
- Storage I/O
В типичных Web2-нагрузках это почти не ощущается, потому что объемы трафика несопоставимо ниже.
Но на Solana одни только подписки на потоки могут приводить к сетевым расходам на сотни долларов в день, и эксплуатация становится экономически неразумной.
Но на Solana одни только подписки на потоки могут приводить к сетевым расходам на сотни долларов в день, и эксплуатация становится экономически неразумной.
Иными словами, большие универсальные облака оказываются несовместимы с Solana не только технически, но и структурно с точки зрения экономики.
Почему ERPC тестировал дата-центры по всему миру
Поняв эти ограничения, мы начали искать инфраструктуру, которая действительно подходит для Solana.
Для этого мы арендовали дата-центры в разных странах и запускали на них реальные Solana-нагрузки.
Даже внутри одного города пригодность площадки для Solana меняется в зависимости от:
- Устройства здания
- Позиции стойки
- Внутренней кабельной схемы
- Набора IXes и transit providers
- Производительности и настроек сетевого оборудования
- Качества ISP и маршрутов
- Объема и качества физических волоконно-оптических маршрутов
- Гарантий полосы пропускания во время перегрузки
В ходе повторяющихся тестов стало очень хорошо видно:
- Какие площадки ведут себя для Solana предсказуемо и стабильно
- А какие не подходят, как бы привлекательно ни выглядели их спецификации
Неподходящие площадки мы последовательно отбрасывали, а удачные - оставляли и масштабировали. Именно на этом накопленном опыте и построен фундамент VPS- и RPC-инфраструктуры ERPC.
Почему VPS от ERPC обеспечивает высокую производительность
Ниже - ключевые архитектурные решения, благодаря которым VPS от ERPC хорошо работает на Solana.
Убираем все лишнее и оставляем только то, что действительно нужно Solana
В больших универсальных облаках много слоев и механизмов, необходимых для поддержки самых разных приложений.
Для Solana большинство этих слоев не приносит прямой пользы и только добавляет задержку.
Для Solana большинство этих слоев не приносит прямой пользы и только добавляет задержку.
ERPC VPS проектировался под Solana-нагрузки, поэтому мы последовательно убрали:
- Слои, не нужные самому трафику Solana
- Компоненты, существующие только ради эксплуатации облака общего назначения
Это не "упрощение ради упрощения", а жесткий принцип:
оставлять только то, что имеет смысл для Solana, и убирать все остальное.
оставлять только то, что имеет смысл для Solana, и убирать все остальное.
CPU последнего поколения и память ECC DDR5
Крупные облака редко открывают для общего доступа CPU последнего поколения.
ERPC VPS, напротив, строится на таких CPU и использует конфигурации того же класса, что применяются в узлах Solana RPC и ShredStream.
ERPC VPS, напротив, строится на таких CPU и использует конфигурации того же класса, что применяются в узлах Solana RPC и ShredStream.
Это позволяет избежать bottlenecks, связанных со старыми поколениями CPU, и дает основу, пригодную для индексирования, торговой логики и аналитики в реальном времени на Solana.
Никакого overcommit
Premium VPS у ERPC никогда не использует overcommit физических CPU-ядер.
Каждое выделенное ядро обеспечено реальным физическим ядром.
Каждое выделенное ядро обеспечено реальным физическим ядром.
Это исключает:
- Плавающую производительность из-за соседних арендаторов
- CPU contention при высокой нагрузке
Даже Standard VPS работает с очень низким уровнем overcommit, чтобы поведение CPU оставалось стабильным.
CPU постоянно работает на максимальном turbo
Во многих серверных средах частота CPU динамически меняется ради экономии энергии или в рамках теплового режима.
Для Solana-нагрузок такая плавающая частота легко становится причиной просадок именно в критический момент.
Для Solana-нагрузок такая плавающая частота легко становится причиной просадок именно в критический момент.
ERPC VPS настраивается так, чтобы CPU постоянно работал на высокой частоте и минимально проседал под нагрузкой. Это дает гораздо более устойчивое поведение.
Размещение в ключевых сетевых точках Solana
ERPC VPS расположен не просто "рядом с нашей собственной инфраструктурой".
Он работает прямо в тех сетях, где в мире сосредоточены Solana validators и основной stake.
Он работает прямо в тех сетях, где в мире сосредоточены Solana validators и основной stake.
Standard VPS размещается в сети, которая занимает второе место в мире по числу валидаторов и объему stake.
Premium VPS работает в сети, которая занимает первое место по обоим показателям и напрямую связана с ключевым узлом, где сходятся лидеры и core validators.
Premium VPS работает в сети, которая занимает первое место по обоим показателям и напрямую связана с ключевым узлом, где сходятся лидеры и core validators.
То есть ERPC VPS:
- Находится в той же сети, что RPC, gRPC и Shredstream инфраструктура ERPC
- И одновременно работает в тех сетях, где концентрация валидаторов и stake максимальна
Это приближает нагрузку и физически, и логически к лидерам.
Поэтому даже один и тот же код и один и тот же алгоритм на ERPC VPS и в обычном облаке чаще всего ведут себя принципиально по-разному, особенно в leader-adjacent detection и отправке транзакций.
RAID0 как осознанный выбор в пользу скорости
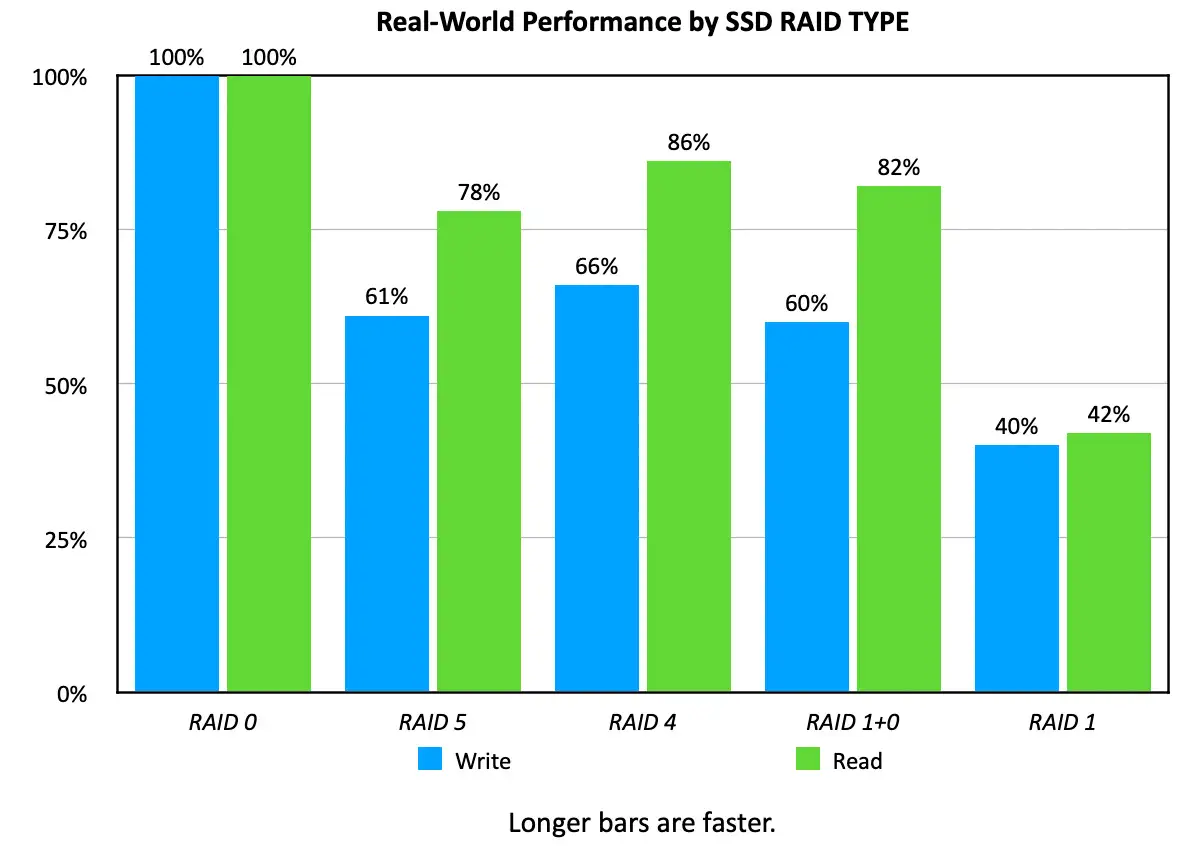
Многие cloud- и VPS-провайдеры ставят в приоритет защиту данных и поэтому выбирают RAID10 или RAID4/5/6.
Для Web2-систем, где пользовательские данные хранятся непосредственно на сервере, это логично.
Для Web2-систем, где пользовательские данные хранятся непосредственно на сервере, это логично.
Но во многих Web3-приложениях и Solana-узлах нет одного уникального и незаменимого набора данных, который существует только на уровне приложения.
Сам блокчейн уже работает как распределенный ledger, а значит повторная синхронизация и пересборка среды в большинстве случаев возможны.
Сам блокчейн уже работает как распределенный ledger, а значит повторная синхронизация и пересборка среды в большинстве случаев возможны.
Кроме того, многие пользователи выбирают производительность вместо зеркалирования, потому что storage I/O напрямую влияет на работу Solana-узла.
Поэтому в ERPC VPS используется RAID0 как способ получить максимальный I/O throughput.
Поэтому в ERPC VPS используется RAID0 как способ получить максимальный I/O throughput.
Для Web3-инфраструктуры в целом важно осознанно решать, где именно нужна redundancy и на каком слое ее имеет смысл строить.
Reference: Real-World Speed Tests for Different SSD RAID Levels
https://larryjordan.com/articles/real-world-speed-results-for-different-raid-levels/
https://larryjordan.com/articles/real-world-speed-results-for-different-raid-levels/
Итог
Производительность VPS от ERPC нельзя объяснить каким-то одним фактором.
Поколение CPU, политика по overcommit, работа в режиме full turbo, выбор дата-центра, сетевые маршруты, RAID-конфигурация и то, насколько тщательно убраны лишние слои под Solana-нагрузки, - каждый из этих пунктов по отдельности может казаться небольшим. Но когда каждый из них доведен до ума, их суммарный эффект и становится тем уровнем производительности, который ERPC VPS обеспечивает сегодня.
Именно так мы построили инфраструктуру, которая принципиально отличается от больших универсальных облаков и специально рассчитана на Web3- и blockchain-нагрузки.
Для Solana эта структурная разница напрямую превращается в ощутимое преимущество по производительности.
Для Solana эта структурная разница напрямую превращается в ощутимое преимущество по производительности.
Если вам нужна консультация по конфигурации, use case или плану развертывания, свяжитесь с нами через Discord Validators DAO.
- Официальный сайт ERPC: https://erpc.global/ru/
- Официальный Discord Validators DAO: https://discord.gg/C7ZQSrCkYR
Новости


