Как устроены потоки данных и протоколы Solana (Shreds, gRPC, WS, UDP)
Как устроены потоки данных и протоколы Solana (Shreds, gRPC, WS, UDP)

Когда вы думаете о том, как ускорить своё Solana-приложение или trading strategy, первым делом стоит прояснить не code и не характеристики сервера.
Стартовать нужно с двух базовых вопросов.
Стартовать нужно с двух базовых вопросов.
Во-первых, насколько далеко вы находитесь от тех Solana validators, которые для вас важны?
В каком регионе фактически живёт ваше приложение и сколько миллисекунд занимает путь до validator оттуда? Именно это расстояние лежит в основе всего. Если с distance ошибка, никакая оптимизация software или hardware не раскроет тот performance, который в принципе возможен.
В каком регионе фактически живёт ваше приложение и сколько миллисекунд занимает путь до validator оттуда? Именно это расстояние лежит в основе всего. Если с distance ошибка, никакая оптимизация software или hardware не раскроет тот performance, который в принципе возможен.
Во-вторых, где находится leader validator в данный момент?
Когда leader во Франкфурт, nodes рядом с Франкфурт получают структурное преимущество. Когда leader в Токио, выигрывают nodes рядом с Токио. Leaders в Solana перемещаются по миру slot за slot, поэтому при single-region setup всегда будут временные окна, где вы физически оказываетесь в проигрышной точке.
Когда leader во Франкфурт, nodes рядом с Франкфурт получают структурное преимущество. Когда leader в Токио, выигрывают nodes рядом с Токио. Leaders в Solana перемещаются по миру slot за slot, поэтому при single-region setup всегда будут временные окна, где вы физически оказываетесь в проигрышной точке.
На практике это означает, что реалистичная стратегия почти всегда должна быть multi-region.
Если разместить инфраструктуру сразу в Франкфурт, Амстердам, Нью-Йорк, Чикаго, Токио и Сингапур, становится возможно наблюдать сеть из региона, который близок к текущему или следующему leader в любом временном диапазоне.
Если разместить инфраструктуру сразу в Франкфурт, Амстердам, Нью-Йорк, Чикаго, Токио и Сингапур, становится возможно наблюдать сеть из региона, который близок к текущему или следующему leader в любом временном диапазоне.
Только поняв этот физический и временной контекст, имеет смысл переходить к самим data streams Solana. В этой статье мы сосредоточимся на трёх вариантах, с которыми чаще всего сталкиваются разработчики:
- WebSocket (WS)
- Geyser gRPC
- Shredstream (UDP Shreds)
Нас интересует, на каком этапе каждый из них видит данные, как именно он их передаёт и для каких задач действительно подходит.
Цель не в том, чтобы выбрать вариант только потому, что «название звучит быстро», а в том, чтобы понять, как работает сама Solana и как поведение протоколов связано с производительностью приложения и UX.
Цель не в том, чтобы выбрать вариант только потому, что «название звучит быстро», а в том, чтобы понять, как работает сама Solana и как поведение протоколов связано с производительностью приложения и UX.
На каком этапе появляются разные виды данных в Solana
Первый шаг - понять, в какой момент внутри внутреннего pipeline Solana становятся видны разные типы данных.
Если упростить, для рассуждений о производительности удобно выделить три стадии.
Если упростить, для рассуждений о производительности удобно выделить три стадии.
Первая стадия - это Shreds.
Validators обмениваются Shreds по UDP, собирая из них blocks. В этот момент по сети ещё идут данные, которые не оформлены в окончательный block. Если вы подключаетесь именно к этому слою, вы видите изменения в сети максимально рано. Но цена за это - необходимость проектировать систему с учётом packet loss и out-of-order arrivals.
Validators обмениваются Shreds по UDP, собирая из них blocks. В этот момент по сети ещё идут данные, которые не оформлены в окончательный block. Если вы подключаетесь именно к этому слою, вы видите изменения в сети максимально рано. Но цена за это - необходимость проектировать систему с учётом packet loss и out-of-order arrivals.
Вторая стадия - Geyser gRPC.
После того как validator получил Shreds, собрал и подтвердил block, он может отдать результат в структурированном виде через Geyser plugins. Именно так и появляются Geyser gRPC streams: они передают blocks, logs, account updates и другие события. По времени это на шаг позже Shreds, но сами данные уже организованы и удобны для приложений.
После того как validator получил Shreds, собрал и подтвердил block, он может отдать результат в структурированном виде через Geyser plugins. Именно так и появляются Geyser gRPC streams: они передают blocks, logs, account updates и другие события. По времени это на шаг позже Shreds, но сами данные уже организованы и удобны для приложений.
Третья стадия - HTTP RPC и WebSocket.
Когда данные проходят через Geyser и внутреннюю обработку node и попадают в её хранилище, они становятся доступны через JSON-RPC и WebSocket notifications. Методы вроде
Когда данные проходят через Geyser и внутреннюю обработку node и попадают в её хранилище, они становятся доступны через JSON-RPC и WebSocket notifications. Методы вроде
getBalance, getProgramAccounts или подписок на logs работают уже с этим сохранённым state. С точки зрения timing это ещё позже, чем у Geyser, и именно этот «верхний публичный API layer» знаком большинству приложений.Если коротко:
- Shreds - это сырые данные почти в момент распространения
- Geyser gRPC - структурированные данные после подтверждения block
- RPC / WebSocket - уже сохранённое состояние, доступное по запросу
Именно то, за каким из этих слоёв вы наблюдаете, определяет, насколько рано можно увидеть изменение в сети. И уже одно это создаёт большой разрыв по performance.
Транспортные особенности: UDP, gRPC, WebSocket и TLS
Timing - это одна ось. Вторая ось - способ доставки данных.
Shreds используют UDP.
У UDP маленькие заголовки и нет этапа установки соединения. Он не гарантирует повторную доставку и порядок пакетов, зато сводит protocol overhead к минимуму. Для таких данных, как Shreds, которые и так распространяются между множеством validators с резервированием, именно такая простота и нужна.
У UDP маленькие заголовки и нет этапа установки соединения. Он не гарантирует повторную доставку и порядок пакетов, зато сводит protocol overhead к минимуму. Для таких данных, как Shreds, которые и так распространяются между множеством validators с резервированием, именно такая простота и нужна.
Geyser gRPC работает поверх TCP и использует бинарный протокол.
Streaming RPC, header compression и binary encoding позволяют передавать данные заметно эффективнее, чем типичный HTTP+JSON. Поэтому gRPC хорошо подходит для постоянного потребления структурированных events в backend systems, monitoring и analytics pipelines.
Streaming RPC, header compression и binary encoding позволяют передавать данные заметно эффективнее, чем типичный HTTP+JSON. Поэтому gRPC хорошо подходит для постоянного потребления структурированных events в backend systems, monitoring и analytics pipelines.
WebSocket обычно работает поверх TCP плюс TLS и передаёт payloads в JSON.
Его главное преимущество - прямая совместимость с браузерами и стандартным web stack, поэтому WS повсюду используется в dApps и лёгких bots. Минус в том, что текстовый JSON надо парсить, а заголовки и шифрование добавляют overhead. Среди этих трёх подходов WebSocket чаще всего оказывается самым тяжёлым.
Его главное преимущество - прямая совместимость с браузерами и стандартным web stack, поэтому WS повсюду используется в dApps и лёгких bots. Минус в том, что текстовый JSON надо парсить, а заголовки и шифрование добавляют overhead. Среди этих трёх подходов WebSocket чаще всего оказывается самым тяжёлым.
Отдельно свою стоимость добавляет TLS.
Если вы используете https, wss или gRPC-TLS, каждое соединение проходит handshake, а payloads нужно шифровать и расшифровывать. Для обычных web apps это чаще всего терпимо. Но в стратегиях, где на UX или PnL влияет каждая десятка миллисекунд, этот overhead уже становится заметен.
Если вы используете https, wss или gRPC-TLS, каждое соединение проходит handshake, а payloads нужно шифровать и расшифровывать. Для обычных web apps это чаще всего терпимо. Но в стратегиях, где на UX или PnL влияет каждая десятка миллисекунд, этот overhead уже становится заметен.
Важно понимать:
- Когда именно вы видите данные (Shreds / Geyser / RPC)
- И как именно они доставляются (UDP / gRPC / WebSocket / TLS)
это две разные вещи, но обе напрямую влияют на финальную latency и UX.
Как соотносятся timing и transport по скорости
Если сложить эти два слоя, картина становится довольно понятной.
С точки зрения timing:
- Самыми ранними идут Shreds
- Затем идёт Geyser gRPC
- Затем RPC / WebSocket
С точки зрения transport:
- Самым лёгким и быстрым остаётся UDP
- Затем идёт gRPC поверх TCP с эффективным binary streaming
- WebSocket с JSON и TLS обычно самый тяжёлый
Если сравнивать при одинаковом регионе, одинаковом железе и одинаковом network path, технический порядок скорости выглядит так:
- UDP (Shreds)
- gRPC (Geyser)
- WebSocket (JSON-RPC notifications)
Но на практике смотреть только на latency нельзя. Нужно учитывать ещё надёжность, требования к корректности, стоимость разработки и ту сложность, которую команда реально готова переварить.
Почему на практике путь чаще WS > gRPC > UDP
Во многих реальных проектах порядок внедрения data streams почти противоположен их «чистой» скорости:
- Сначала WebSocket
- Потом Geyser gRPC
- Потом Shreds / UDP
Это абсолютно закономерно.
Shreds (UDP) действительно самый быстрый слой, но он требует изначально проектировать систему с учётом пропусков, out-of-order данных и шумного потока.
Нельзя исходить из того, что каждый пакет обязательно дойдёт и что всё придёт идеально в линию. Приходится закладывать reconciliation, работу с gaps и устойчивость к шуму. Взамен вы получаете минимальную latency, но и заметный рост сложности.
Нельзя исходить из того, что каждый пакет обязательно дойдёт и что всё придёт идеально в линию. Приходится закладывать reconciliation, работу с gaps и устойчивость к шуму. Взамен вы получаете минимальную latency, но и заметный рост сложности.
Geyser gRPC отдаёт уже подтверждённые и структурированные данные, сформированные внутри node.
Из-за этого его намного проще использовать. Event-driven backends, alerting systems, on-chain analytics и indexers отлично строятся на Geyser, потому что он даёт хороший баланс между скоростью, надёжностью и стоимостью внедрения. Для многих команд это естественный второй шаг после WebSocket-only схем.
Из-за этого его намного проще использовать. Event-driven backends, alerting systems, on-chain analytics и indexers отлично строятся на Geyser, потому что он даёт хороший баланс между скоростью, надёжностью и стоимостью внедрения. Для многих команд это естественный второй шаг после WebSocket-only схем.
Преимущество WebSocket в том, что он прямо подключается к браузерам и стандартной web-инфраструктуре.
dApp frontends и небольшие сервисы могут использовать его с привычными инструментами и библиотеками, а примеров и документации очень много. Поэтому для первого запуска продукта WebSocket часто оказывается самым рациональным вариантом, особенно если вы уже решили проблему distance до validators.
dApp frontends и небольшие сервисы могут использовать его с привычными инструментами и библиотеками, а примеров и документации очень много. Поэтому для первого запуска продукта WebSocket часто оказывается самым рациональным вариантом, особенно если вы уже решили проблему distance до validators.
То есть в теории скорость идёт так: UDP > gRPC > WS.
А на практике внедрение чаще идёт так: WS > gRPC > UDP.
Обе логики правильны, и выбирать нужно не «самое быстрое название», а вариант под вашу стадию проекта и текущую экономику.
А на практике внедрение чаще идёт так: WS > gRPC > UDP.
Обе логики правильны, и выбирать нужно не «самое быстрое название», а вариант под вашу стадию проекта и текущую экономику.
Как Shreds и Geyser gRPC работают вместе
Как только команда перестаёт просто «подкручивать скорость» и начинает считать каждые десятки миллисекунд, главный вопрос меняется: как правильно комбинировать Shreds и Geyser gRPC.
Shreds нужны, чтобы заметить событие первыми.
Если вы получаете Shreds рядом с текущим leader, можно увидеть изменения в сети на десятки или даже сотни миллисекунд раньше, чем тот, кто смотрит только на Geyser или RPC. Для стратегий, где этот разрыв напрямую превращается в PnL, это критично. Но при этом приходится принимать шум и строить систему под него.
Если вы получаете Shreds рядом с текущим leader, можно увидеть изменения в сети на десятки или даже сотни миллисекунд раньше, чем тот, кто смотрит только на Geyser или RPC. Для стратегий, где этот разрыв напрямую превращается в PnL, это критично. Но при этом приходится принимать шум и строить систему под него.
Geyser gRPC нужен, чтобы подтверждать картину и принимать решения на устойчивых данных.
В момент подтверждения block Geyser отдает logs, account changes и другие структурированные события. На их основе удобно строить основную strategy logic, risk controls, indexers и monitoring. Он медленнее Shreds, зато данные в нём намного проще интерпретировать.
В момент подтверждения block Geyser отдает logs, account changes и другие структурированные события. На их основе удобно строить основную strategy logic, risk controls, indexers и monitoring. Он медленнее Shreds, зато данные в нём намного проще интерпретировать.
Поэтому в реальных системах часто используется такая схема:
- Shreds отвечают за ранний detection и сбор кандидатов на действия
- Geyser gRPC параллельно отвечает за подтверждение blocks, logs и основную логику
Такой раздел позволяет давить latency, не теряя опору на данные, которые удобно проверять и интерпретировать.
TLS, shared endpoints и dedicated nodes
До сих пор мы предполагали, что underlying node и network одинаковы. Но в реальности есть ещё одно огромное отличие: работаете вы с shared endpoint или с dedicated node.
Shared endpoint используется сразу многими клиентами.
Он выставлен в публичный интернет и всегда проходит через security perimeter. Поэтому шифрование обязательно, отключить TLS нельзя. Для обычных dApps это нормально, но в HFT-подобных задачах любая лишняя десятка миллисекунд уже заметна.
Он выставлен в публичный интернет и всегда проходит через security perimeter. Поэтому шифрование обязательно, отключить TLS нельзя. Для обычных dApps это нормально, но в HFT-подобных задачах любая лишняя десятка миллисекунд уже заметна.
Dedicated node закреплён за одним клиентом.
Поскольку доступ можно ограничить по IP и изолировать environment, появляется возможность отказаться от TLS и использовать plain HTTP или plaintext gRPC. Кроме того, CPU, memory, disk I/O и network bandwidth больше не делятся с соседями, а значит latency не «прыгает» из-за чужих нагрузок.
Поскольку доступ можно ограничить по IP и изолировать environment, появляется возможность отказаться от TLS и использовать plain HTTP или plaintext gRPC. Кроме того, CPU, memory, disk I/O и network bandwidth больше не делятся с соседями, а значит latency не «прыгает» из-за чужих нагрузок.
Если Shreds, Geyser gRPC и RPC работают на dedicated nodes, весь этот стек живёт в изолированной среде без соседних клиентов и без TLS overhead.
Именно это позволяет dedicated setups достигать диапазона latency, куда shared endpoints по своей природе выйти не могут, даже на том же hardware.
Именно это позволяет dedicated setups достигать диапазона latency, куда shared endpoints по своей природе выйти не могут, даже на том же hardware.
Shared nodes существуют для того, чтобы давать хорошую производительность большому числу пользователей.
Dedicated nodes нужны там, где действительно надо дойти до предельной скорости.
Dedicated nodes нужны там, где действительно надо дойти до предельной скорости.
Multi-region и dedicated Shreds (UDP forwarding)
Пока leaders в Solana продолжают вращаться по миру, single-region setup не сможет быть самым быстрым везде и всегда.
Именно здесь на сцену выходят multi-region Shreds setups.
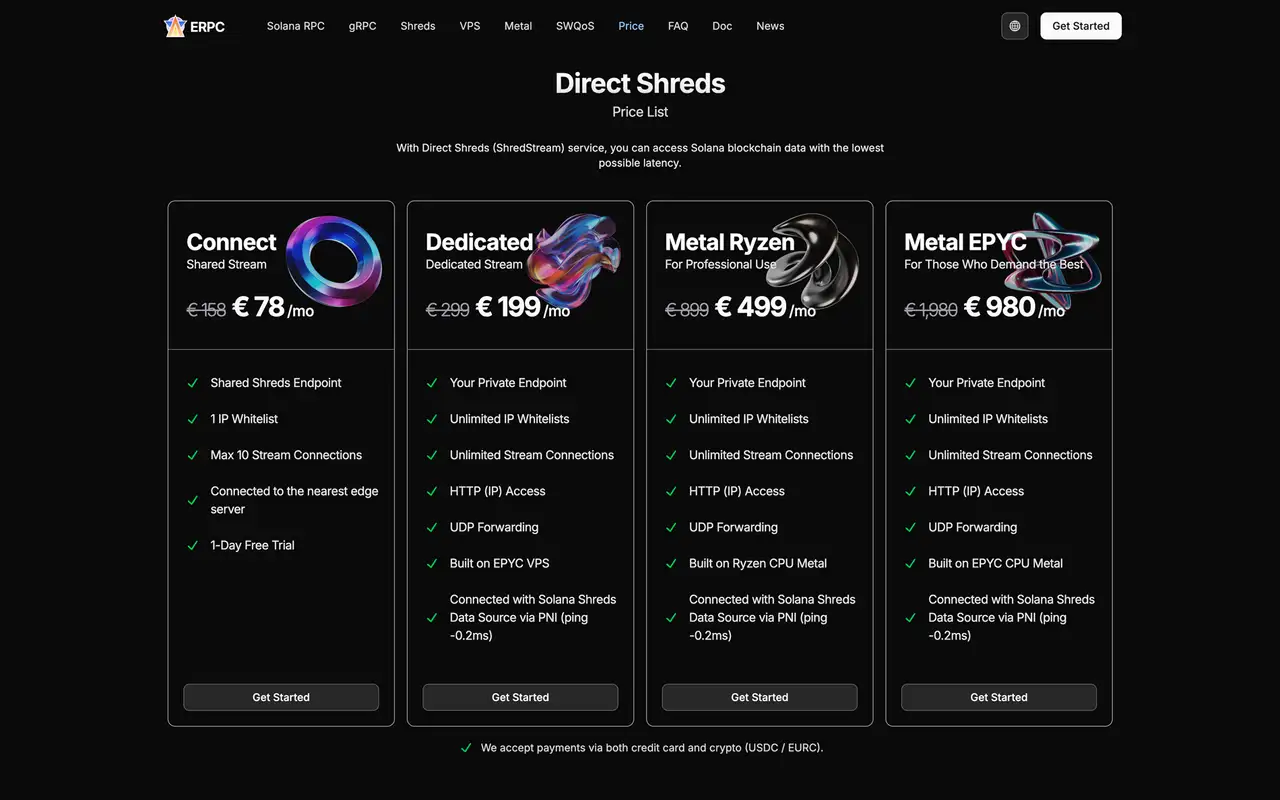
Dedicated Shreds (Premium Shreds, Standard Shreds, Metal Shreds, Limited Editions и другие серии) сочетают:
- Максимально быструю доставку Shreds по UDP
- Dedicated servers с минимальным jitter
Если разместить dedicated Shreds сразу в Франкфурт, Амстердам, Нью-Йорк, Чикаго, Токио и Сингапур, можно получать Shreds рядом с leader независимо от того, какой регион сейчас оказывается самым выгодным.
Обычный production pattern здесь такой: система одновременно подписывается на несколько потоков Shreds из разных регионов и реагирует только на тот, который пришёл первым.
Это снижает влияние long-haul latency и региональной перегрузки и позволяет на практике приблизиться к состоянию «почти всегда близко к leader».
Это снижает влияние long-haul latency и региональной перегрузки и позволяет на практике приблизиться к состоянию «почти всегда близко к leader».
Чтобы multi-region dedicated Shreds было проще внедрять, ERPC предлагает скидки за использование нескольких регионов:
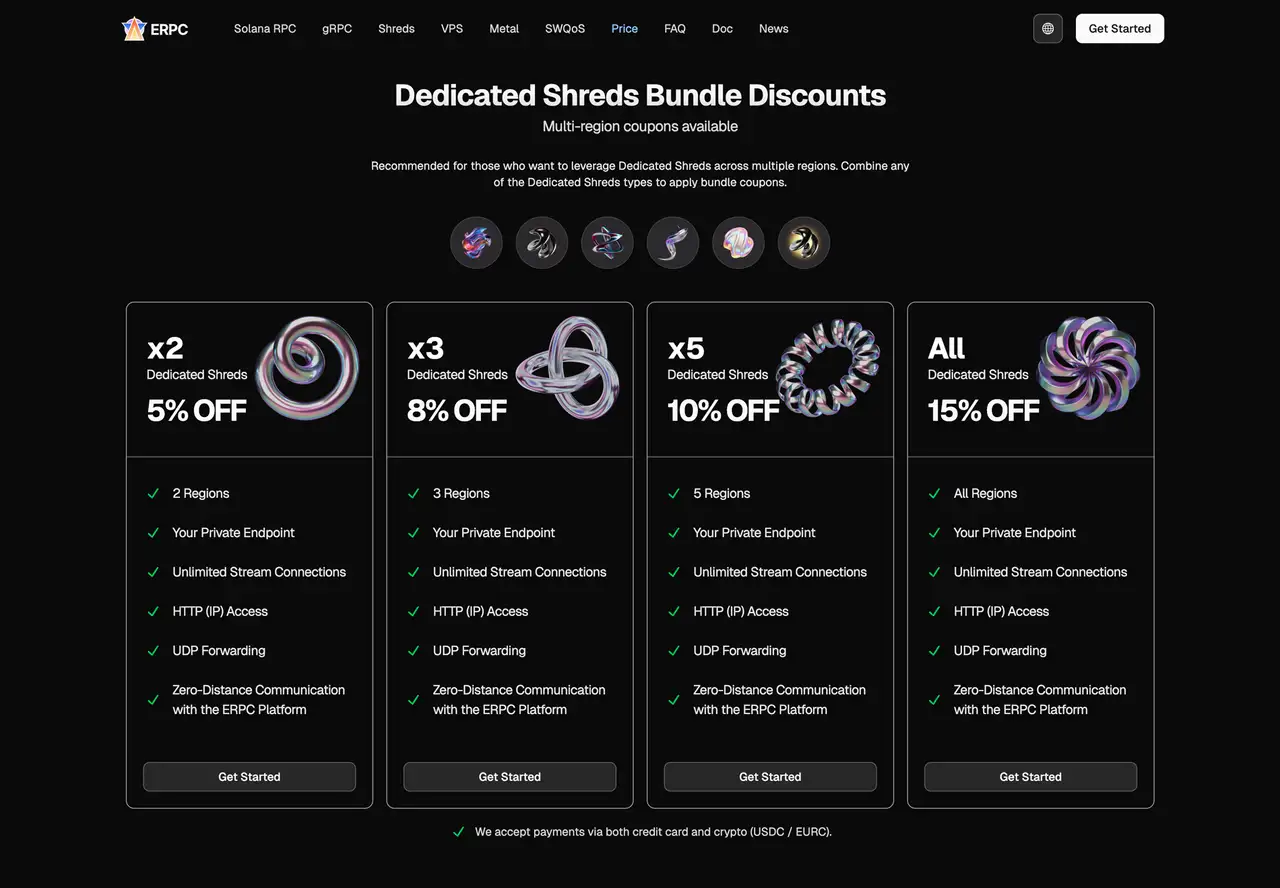
- 2 regions: 5% off
- 3 regions: 8% off
- 5 regions: 10% off
- All regions: 15% off
Это позволяет поставить самые premium Shreds tiers (например, Premium или Metal) в наиболее конкурентных регионах, а в вспомогательных точках использовать более доступные варианты, но всё равно сохранить широкое покрытие.
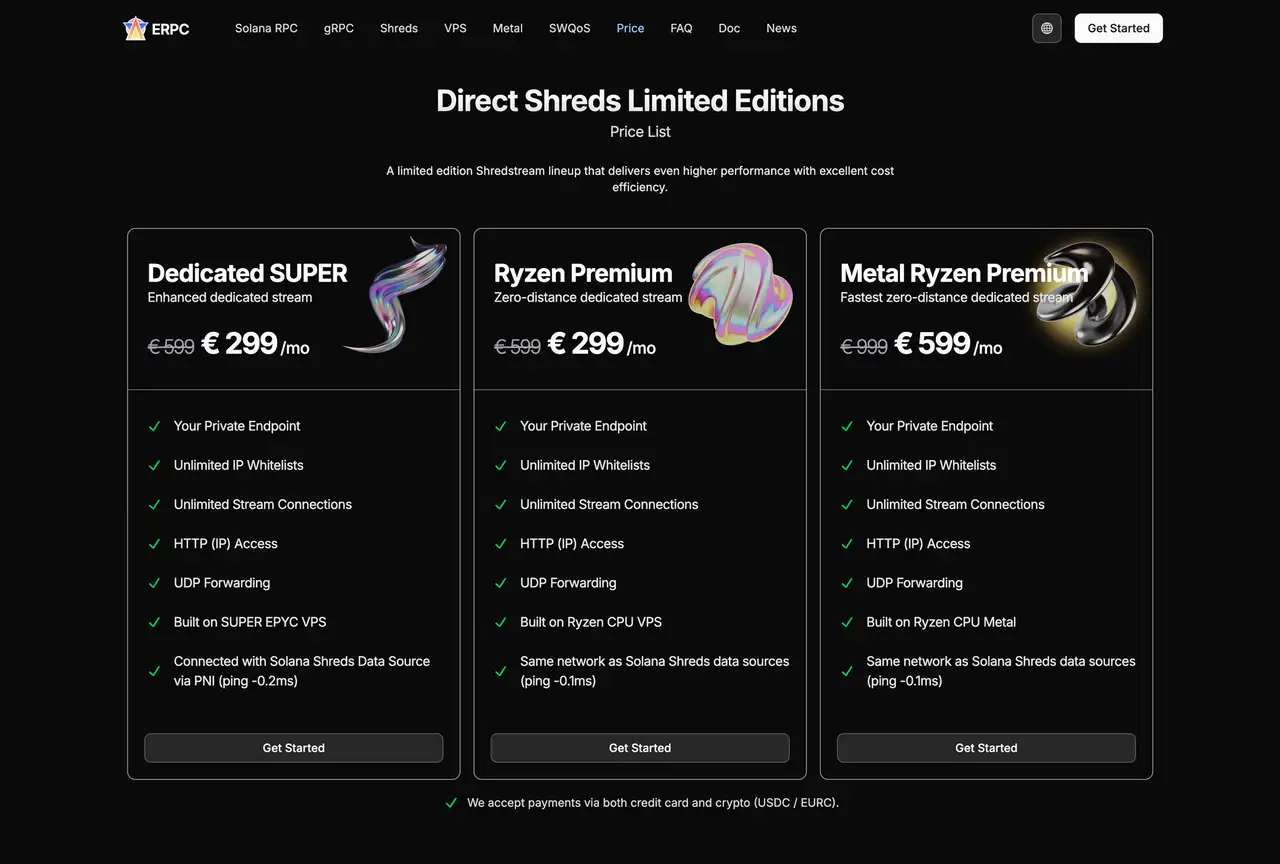
Shared Shredstream Bundles как более широкий вход в мир Shreds
Прежде чем идти в fully dedicated Shreds everywhere, часто полезно пройти промежуточный этап через multi-region Shared Shredstream.
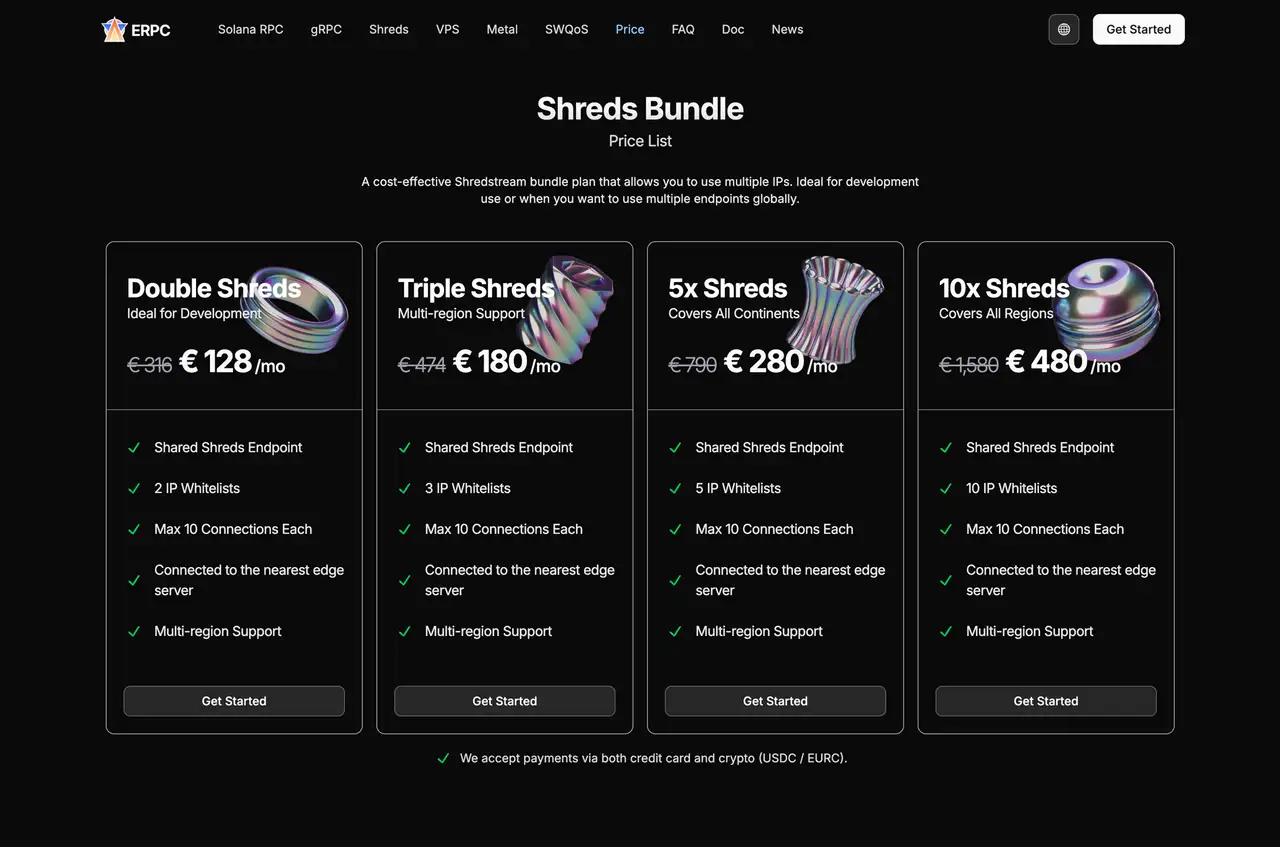
Shared Shredstream Bundles дают доступ к shared Shreds из нескольких регионов по одному плану.
Внутри такой схемы данные всё равно приходят из слоя Shreds (UDP), а до клиента доходят в виде gRPC. То есть источник остаётся «ранним», но пользоваться им проще.
Внутри такой схемы данные всё равно приходят из слоя Shreds (UDP), а до клиента доходят в виде gRPC. То есть источник остаётся «ранним», но пользоваться им проще.
Если выстроить слои по времени, получится так:
- Dedicated Shreds через UDP forwarding - самый быстрый слой
- Shared Shredstream - gRPC-поток, построенный поверх Shreds
- Geyser gRPC - следующий уровень, уже после этого
Shared Shredstream Bundles включают IP whitelisting, 10 connections и автоматическую маршрутизацию к ближайшему edge. Это позволяет недорого получить Shreds-based data сразу в Азии, Европе и Северной Америке.
Поэтому вместо резкого перехода к dedicated Shreds во всех регионах можно действовать поэтапно:
- Начать с Shared Shredstream Bundle и получить реальный опыт работы с Shreds-based data
- Собрать логи и понять, где это действительно меняет результат
- Перевести самые важные регионы на dedicated Shreds, когда для этого уже есть данные и business case
Практические шаги по стадиям развития
Если собрать всё вместе, становится проще мыслить не технологиями, а этапами.
На первом этапе важно выбрать правильный регион и минимальную distance, а затем строить dApp или bot на RPC и WebSocket.
Уже один только правильный выбор региона часто заметно улучшает UX ещё до внедрения Shreds или gRPC. Для старта продукта WebSocket очень рационален, особенно во frontend.
Уже один только правильный выбор региона часто заметно улучшает UX ещё до внедрения Shreds или gRPC. Для старта продукта WebSocket очень рационален, особенно во frontend.
На втором этапе имеет смысл добавить Geyser gRPC для backend, monitoring и analytics.
Geyser gRPC позволяет эффективно получать blocks, logs и account events и строить на них indexers, alerting systems и внешние APIs. Это естественный «второй шаг» для многих команд.
Geyser gRPC позволяет эффективно получать blocks, logs и account events и строить на них indexers, alerting systems и внешние APIs. Это естественный «второй шаг» для многих команд.
На третьем этапе стоит подключать Shreds и UDP forwarding там, где разница в latency напрямую влияет на PnL или UX.
Развёртывание dedicated Shreds сразу в нескольких регионах и использование скидок делает возможным выход в диапазон latency, который требуется для HFT, MEV и 0-slot strategies.
Развёртывание dedicated Shreds сразу в нескольких регионах и использование скидок делает возможным выход в диапазон latency, который требуется для HFT, MEV и 0-slot strategies.
Суть не в том, что «UDP теоретически быстрее, значит нужен только UDP».
Суть в том, чтобы понимать собственную стадию проекта и экономику, и только после этого решать, где инвестиции в Shreds и dedicated infrastructure действительно дают эффект.
Суть в том, чтобы понимать собственную стадию проекта и экономику, и только после этого решать, где инвестиции в Shreds и dedicated infrastructure действительно дают эффект.
Bundle и VPS от ERPC как базовый фундамент
Bundle plans ERPC изначально построены как единая основа:
- RPC (HTTP / WebSocket)
- Geyser gRPC
- Shared Shredstream gRPC
в одной общей структуре.
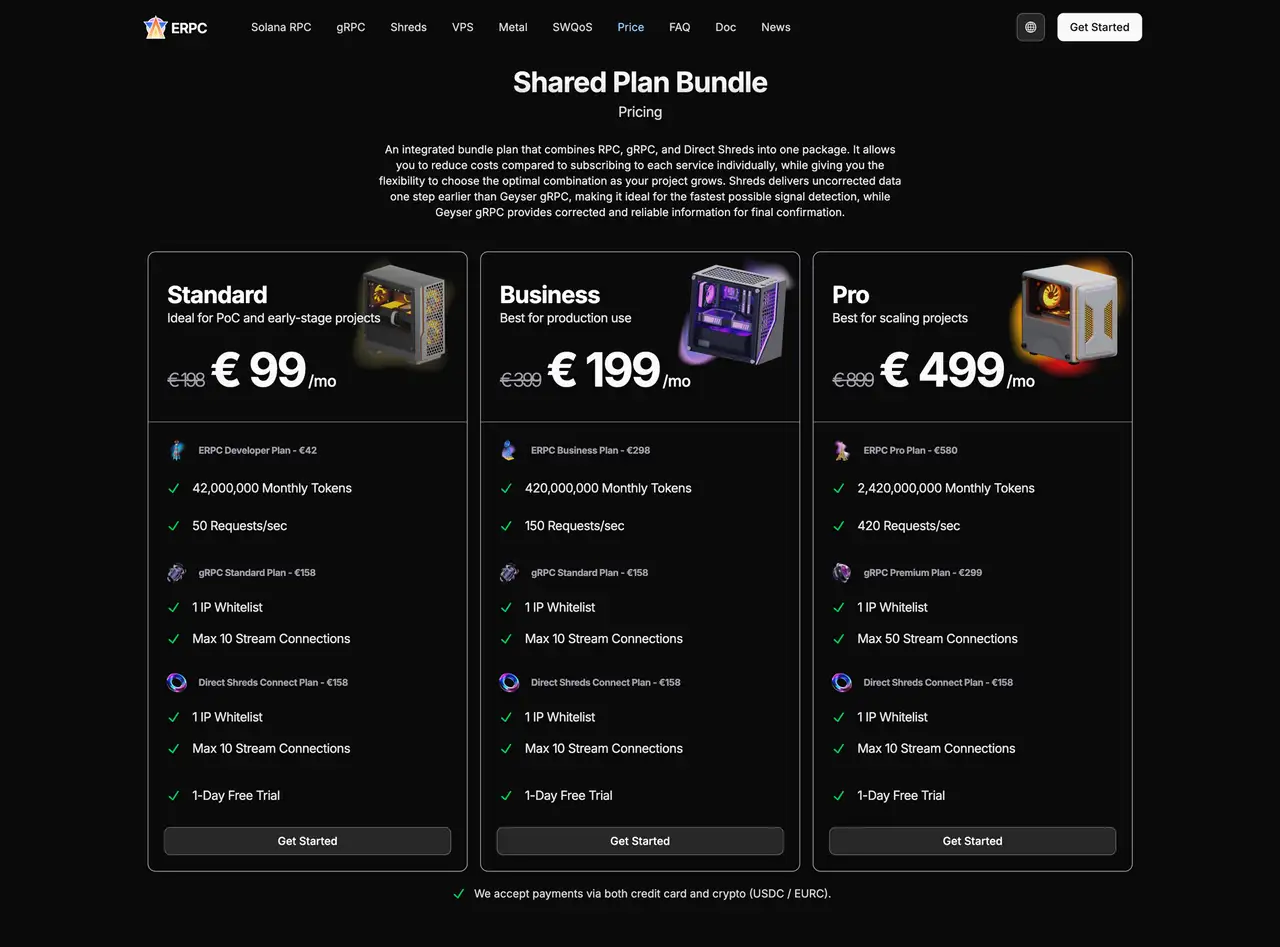
Это позволяет продолжать использовать RPC и WebSocket как основной production interface и параллельно экспериментировать с Geyser gRPC и Shredstream в той же сети.
Поскольку всё работает на общей инфраструктуре, решения можно принимать по реальным измерениям, а не по ожиданиям.
Поскольку всё работает на общей инфраструктуре, решения можно принимать по реальным измерениям, а не по ожиданиям.
Поверх этого Bundle можно сочетать с VPS внутри той же сети ERPC, включая EPYC VPS и Premium Ryzen VPS.
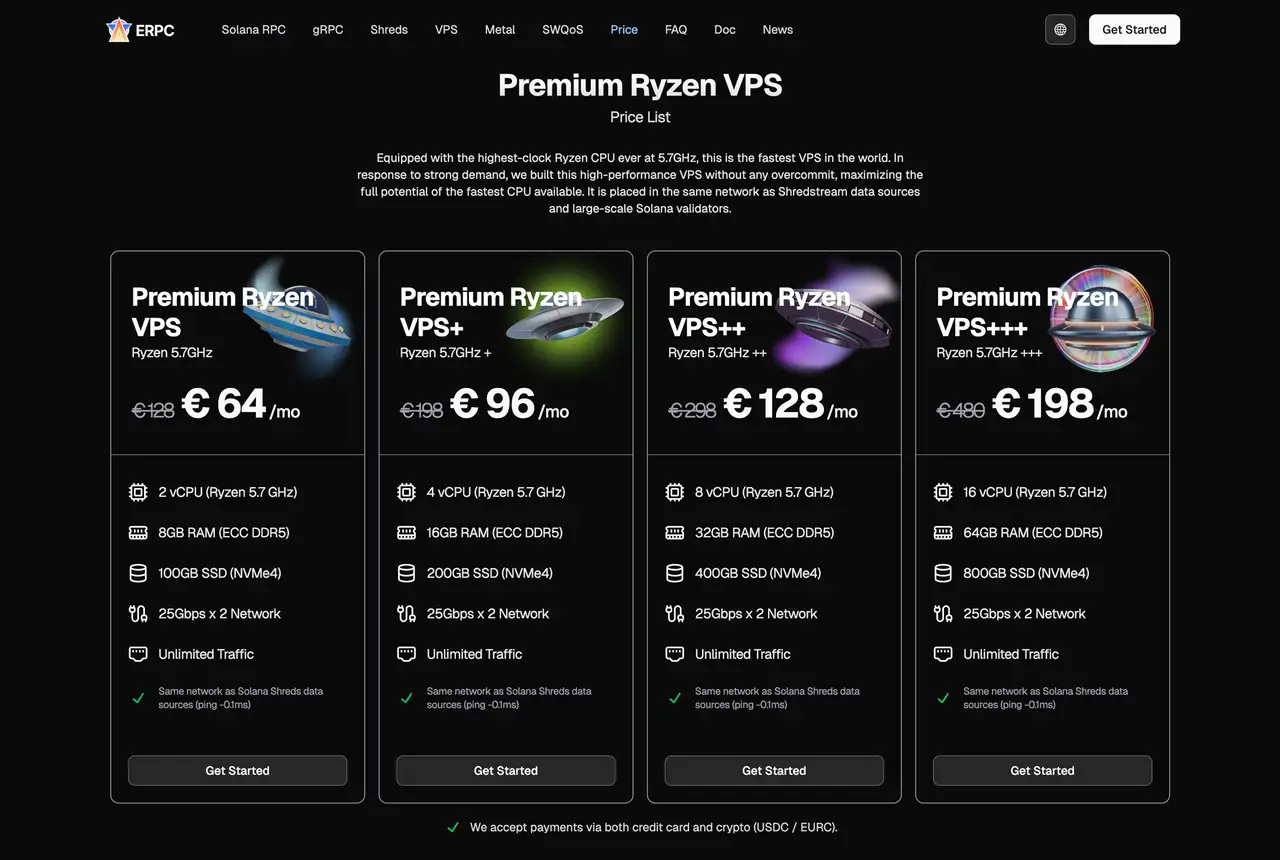
Так можно в одном месте настраивать:
- Distance до Solana validators
- Набор data streams (WS, gRPC, Shreds)
- Hardware performance
На практике удобный путь выглядит так: сначала закрепить нужные регионы и базу Bundle + VPS, а затем включать более быстрые слои - Geyser, Shared Shreds и dedicated Shreds - по мере роста задач и бюджета.
Итог: Solana performance строится на timing, transport и distance
Производительность и UX в Solana-приложении складываются из нескольких вещей одновременно:
- Где физически стоят ваши servers
- Насколько близко вы к leader в нужные временные окна
- На каком этапе вы получаете данные
- Через какой transport и protocol они приходят
- И как поверх этого реагирует business logic
Distance и положение leaders - это базовый слой. Поверх него идут:
- Shreds как самый ранний источник
- Geyser gRPC как слой структурированных подтверждённых данных
- RPC / WebSocket как API-доступ к сохранённому состоянию
А по transport side вы выбираете между:
- UDP
- gRPC over TCP
- WebSocket over TCP with JSON and TLS
Выбирать data stream или protocol только по названию или маркетинговому тезису недостаточно.
Важно подбирать архитектуру под свой use case по трём осям сразу: timing, transport characteristics и distance до нужных validators.
Важно подбирать архитектуру под свой use case по трём осям сразу: timing, transport characteristics и distance до нужных validators.
ERPC и Validators DAO дают для этого Solana-focused network, RPC / gRPC / Shredstream services, VPS-линейку и скидки на multi-region dedicated Shreds, чтобы такие архитектуры можно было строить по реальной, а не теоретической экономике и развивать их по мере роста задач.
Если вы хотите обсудить архитектуру data streams, оптимизацию network distance или комбинацию dedicated Shreds, Shared Shredstream Bundles, Bundle plans и VPS, можно обратиться через Discord Validators DAO.
- ERPC: https://erpc.global/en
- SLV: https://slv.dev/en
- Epics DAO: https://epics.dev/en
- Validators DAO Discord: https://discord.gg/C7ZQSrCkYR
Новости